具備怎樣特質的計程車司機是最賺錢的呢?(開頭都這句哈哈)
今天繼續努力做資料處理,昨天我本來想用迴圈處理所有變數,看樣子我太天真了,想要整理好數據,看樣子還是得把所有變數都看過一輪才行(好像也是可以不用啦,但我想把變數都釐清在開始作業),但重點還是因為他的空值亂七八糟(參照[Day 2]),讓我覺得很痛苦。
總之我很直觀的看過半輪變數名稱(149個變數看一半而已)(抱歉明天估計是把另外一半處理完...沒有在混啦而且我估計這段是最累的部分了),把一些完全無關緊要的刪掉然後用上一篇for迴圈控制大量使用RCODE進行vlookup,成品大概長這樣。看起來清楚多了!
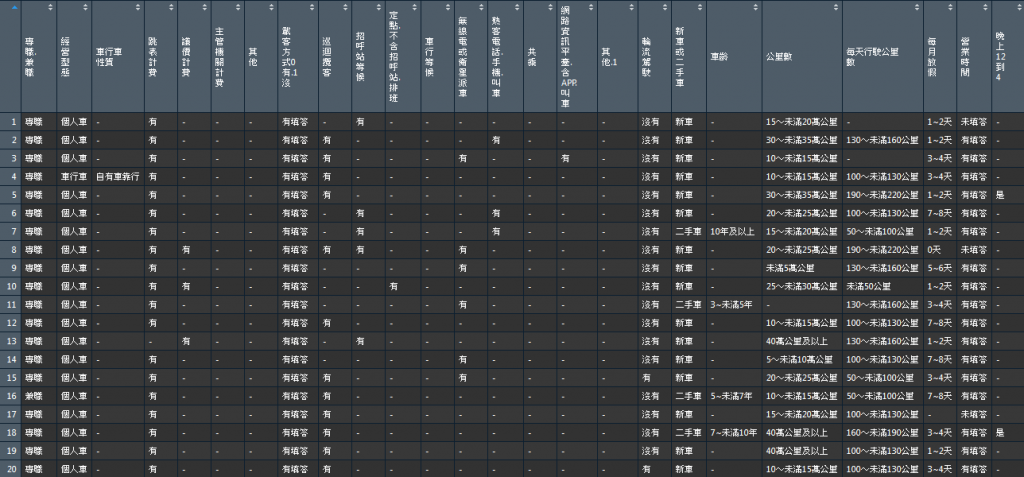
不然原本的data我對他一點想法都沒有..
分享一下在處理資料的心得吧,雖然是寫r_code,但如果Excel處理更快的話,請善用Excel不要裝逼。
操作上比較值得一提的部分
x = read.csv("106年計程車營運狀況調查原始資料csv")[1:20,]
因為是測試階段,在後面打[1:20,]只顯示前20行可以讓速度快很多,或是用as.tibble()也行。
library(psych)
q = read.table("clipboard",header = F , sep = '\t')
zz = parse_guess(unlist(q))
describe(zz)
boxplot(zz,
main="計程車司機一天營業總收入",
ylab = "金額",
col ="gray"
)
hist(parse_guess(unlist(q)))
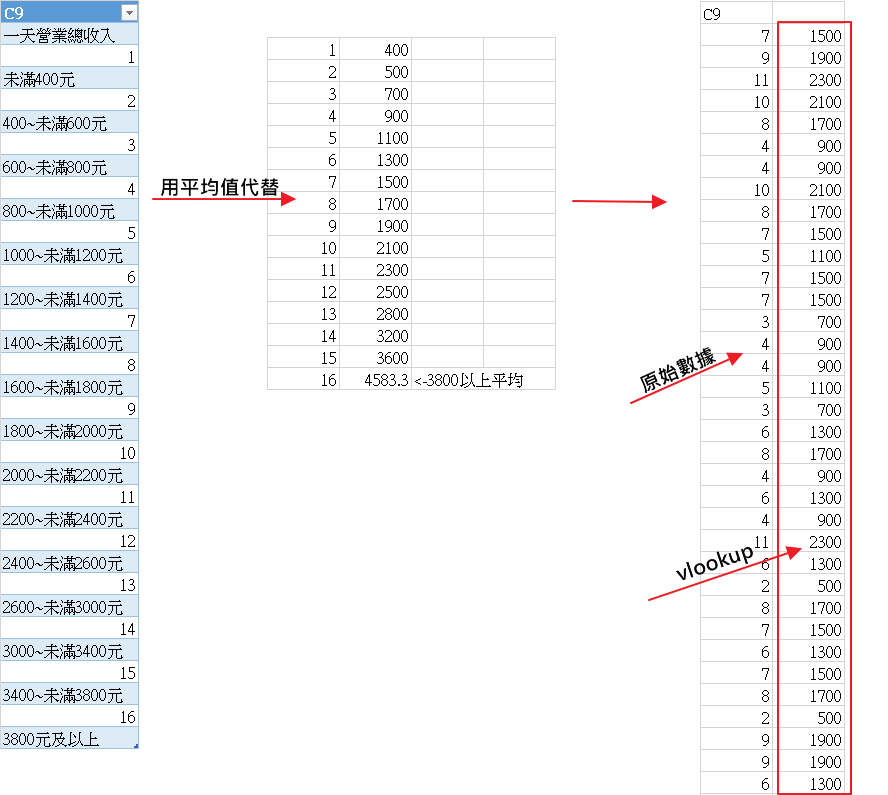
稍微用R_code看看計程車司機的收入分配,vlookup完之後可以直接複製vlookup那行,跑第二行,q就會是複製的資料,然後這筆資料R不認為他是數字(可能後面有1500.0所以R以為他是文字),所以要打parse_guess()讓R"猜"出他是數字才能運算這筆資料
基本的敘述性統計describe,然後附上R的合型圖以及hist圖
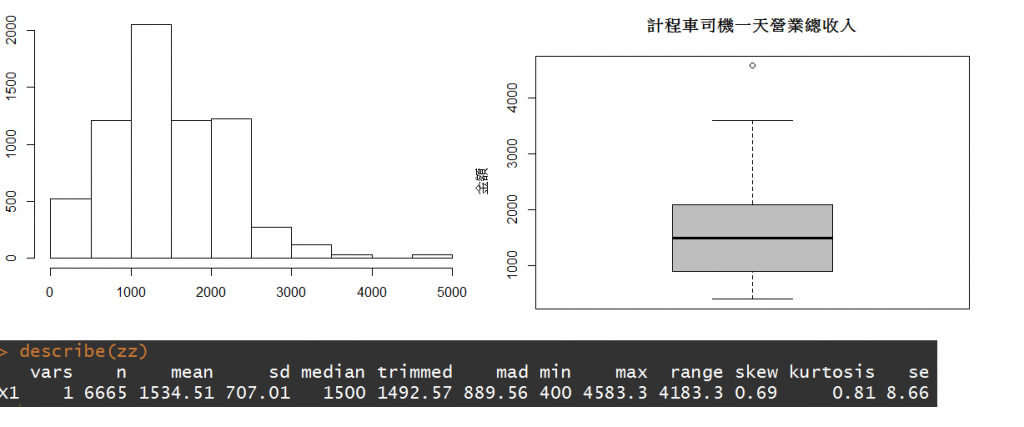
各位明天見!(再...再讓我資處兩天...之後會很好玩的!)

